In Teil 2 haben wir beschrieben, wie wir mithilfe von künstlicher Intelligenz Textdaten aufbereitet und vektorisiert haben. Die so aufbereiteten Dateien konnten wir so am Ende des Prozesses für das Dokumenten-Clustering verwenden.
Das Dokumenten-Clustering
Dieser Lösungsansatz eignet sich besonders gut, wenn kaum Informationen über die Verteilung der Daten existieren und eine Ordnung gefunden werden muss. Man spricht dabei von „unsupervised-learning”-Problemen. Durch den Vorgang werden verschiedene Arten von Ähnlichkeiten aufgedeckt.

Gerade bei kleineren Datenmengen eignet sich das hierarchische Clustering. Dabei werden alles Dokumente miteinander verglichen und auf Ähnlichkeiten geprüft. Die Berechnungszeit steigt dabei exponentiell mit der Anzahl der Dokumente. Für größere Datenmengen ist der sogenannte „K-Means Algorithmus” in der Regel die bessere Wahl. Es handelt sich um einen „partitionierenden Clusteralgorithmus”, wobei festgelegt werden muss, wie viele Cluster aus den Dokumenten erstellt werden sollen.
Topic Models
Während die Dokumente beim Clustering vor allem nach Dokumententypen gruppiert werden – also z.B. E-Mails, Verträge, Rechnungen etc. – geht es beim Topic Modelling darum, Themen aus den Dokumenten zu extrahieren. Ein einzelnes Dokument kann dabei auch mehrere Themen enthalten und ein Thema kann in verschiedenen Dokumententypen vorkommen. Die Gesamtanzahl aller Topics muss dabei im Vorhinein festgelegt werden.
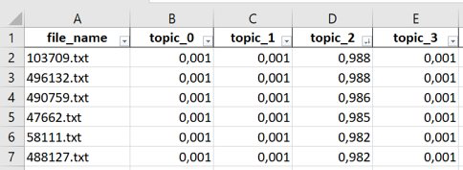
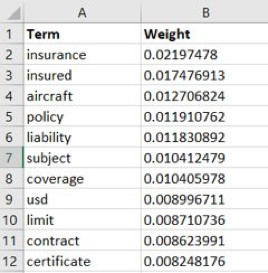
Die erste Tabelle zeigt ein Topic mit seinen zugehörigen Wörtern und deren entsprechenden Wahrscheinlichkeiten. Als Betrachter kann man erkennen, dass es sich bei diesem Topic um das Thema „Versicherungen“ handelt.
Die zweite Tabelle zeigt die Wahrscheinlichkeitsverteilung, also die Verteilung der Topics innerhalb eines Dokuments. Enthält das Dokument nur ein Topic, hat dieses eine sehr hohe Wahrscheinlichkeit, während der Wert für die restlichen Topics annähernd null ist. Bei mehreren Themen im Dokument verteilt sich die Wahrscheinlichkeit auf alle diese Themen.
Ergebnisse zu Anfechtungsansprüchen
Als Ergebnis dieser Vorgänge konnten wir aus riesigen Datenmengen eine Reihe von wichtigen Anfechtungsbeständen definieren.
Mithilfe des Clusterings haben wir mittels Wordclouds für das ISR-Project relevante Themen und Aspekte visualisiert. Unabhängig vom Dokumententyp konnten wir damit anhand von Inhalten die Anfechtungstatbestände ausmachen. Konkrete Vorgänge in E-Mail-Daten konnten so mit den Daten und Transaktionen aus der Buchhaltung verknüpft werden und damit belegbar gemacht werden.

Darüber hinaus haben wir anschließend zugehörige Dokumente im DMS-System (z.B. Bestellungen, Lieferungen, Wareneingänge, Eingangsrechnungen) ermittelt, die als Nachweis fungierten. Auf diese Art und Weise wurde eine lückenlose Beweiskette geschaffen und wir konnten mithilfe von Künstlicher Intelligenz die sprichwörtliche Nadel im Heuhafen finden.
Lesen Sie mehr zu diesem Thema in Teil 4 unserer Case Study zum Thema „Der praktische Nutzen von Big Data in Krisenunternehmen”!